16 KiB
| author | title | date | papersize | documentclass | classoption | mainfont | sansfont | fontsize | toc | header-includes | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Carl Kittelberger | ITS: Hypertext Transfer Protocol | 2018-01-25 | a4 | report | oneside | Arial | Arial | 12pt | true |
|
\newpage
Definition
HTTP (HyperText Transfer Protocol) ist ein Standard, der festlegt wie Webseiten über das Internet übertragen werden. Es definiert ein Protokoll auf der Sitzungsschicht des OSI-Schichtenmodells, welches auf Basis des TCP/IP-Stacks läuft.
Das Protokoll an sich definiert die Übertragung der Anfrage und der Antwort im Klartext. Dies soll die konsistente Implementierung deutlich vereinfachen.
Jedoch wird HTTP heutzutage oft in anderen Protokollen eingebettet wie zum Beispiel TLS für den sicheren, verschlüsselten Zugriff auf eine Website oder auch Tor für dezentralisierte, anonymisierte Zugriffe auf Websites.
Geschichte
Entwickelt wurde HTTP als Teil des Webprojekts an der Forschungseinrichtung CERN von Tim Berners-Lee, Roy Fielding und anderen Teilnehmern. Die erste bekannte Version von HTTP war die Version 0.9.
HTTP/0.9
Diese frühe Version von HTTP definiert ein Subset des kompletten Protokolls als Prototyp und wurde bereits so entworfen, dass zukünftige Versionen von HTTP rückwärtskompatibel mit dieser sind.
Hier wurden bereits fundamentale Eigenschaften des Protokolls, wie dessen Abhängigkeit vom TCP/IP-Stack, der Port 80 für Datenaustausch sowie das Nutzen von ASCII-Klartext festgelegt. Nach jeder Anfrage, die verarbeitet wurde, wurde die Verbindung direkt wieder geschlossen.
HTTP/1.0
Diese Version von HTTP ist die meistgenutzte Version für die einfachsten Anfragen zu Webservern und ist die erste mit einer vollständigen Spezifikation. Sie unterstützt unter anderem die Kodierung von Inhalten mit GZip/Compress.
HTTP/1.1
Die Version 1.1 von HTTP wurde 1999 unter der RFC 2616
publiziert. Neuerungen in dieser Version sind unter anderem das Wiederverwenden
einer bereits aufgebauten HTTP-Verbindung über mehrere HTTP-Anfragen hinweg
erlaubt (siehe Keep-Alive Header später). Außerdem erlaubt diese Version
auch das Herunterladen von Teilen einer Datei anstatt die gesamte Datei
herunterladen zu müssen, um zum Beispiel bereits angefangene Übertragungen
nahtlos fortzusetzen.
Es werden auch weitere HTTP-Methoden neben GET und POST eingeführt, die
für das direkte Speichern, Löschen und Verwalten von Dateien auf einem Server
geeignet sind. Diese Methoden werden vor allem bei WebDAV eingesetzt.
Später wurden über mehrere RFCs hinweg (7230-7235) einige Aspekte von HTTP/1.1 noch einmal klarer spezifiziert um Unklarheiten zur Implementierung zu beseitigen.
HTTP/2
Zu dieser im Mai 2015 von der IETF verabschiedeten Version von HTTP wurde maßgeblich beigetragen von Google und Microsoft, die jeweils Versuche gemacht haben, HTTP in Hinsicht auf Geschwindigkeit und Latenz zu verbessern. Ein bekannter und grundgebender Vorgänger dieser Version war das von Google kreierte SPDY-Protokoll.
In dieser Version können mehrere Anfragen zusammengefasst werden ("Multiplex") und dann zum Beispiel gemeinsam inklusive Headerdaten komprimiert werden, Inhalte können binär kodiert übertragen werden und der Server kann von sich aus Inhalte in den Client vorladen ("push"-Verfahren).
HTTP/2 funktioniert — obwohl die Spezifikation das mittlerweile nicht mehr strikt einschränkt — so gut wie nur noch auf TLS-verschlüsselten Verbindungen ("HTTPS"). Hintergrund ist der Gedanke, dass Verbindungen grundsätzlich verschlüsselt sein sollten um vor allem Man-In-The-Middle-Attacken (MITM) und ähnliche unerlaubte Zugriffe auf Klartextbasis zu verhindern.
Diese Version von HTTP wird in der Analyse nicht behandelt, da die Verschlüsselung und binäre Kodierung den Rahmen des Dokuments sprengt.
Analyse
Die Analyse der Anfragen findet auf der obersten OSI-Schicht statt, also wird nur der Inhalt der eigentlichen Anfrage analysiert, nicht die Daten auf TCP-, IP- oder Ethernet-Schicht.
Zum Auslesen der Anfragen und Antworten wird die Software Wireshark verwendet, die vorher wie im folgenden Screenshot konfiguriert wurde:
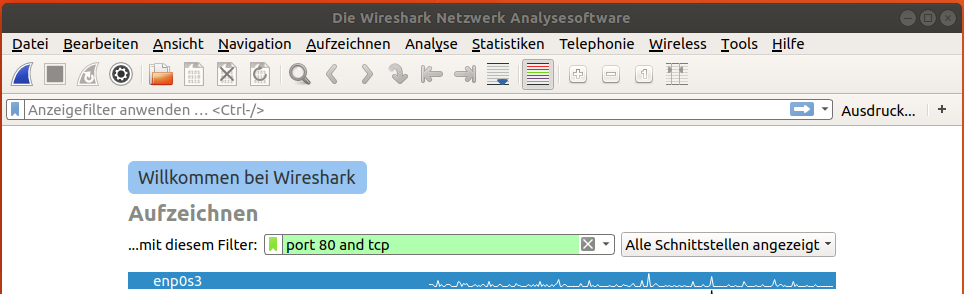
Jede HTTP-Anfrage wird in einer TCP-Verbindung gekapselt, entsprechend wird zuerst mit TCP jeweils eine Verbindung per SYN-/ACK-Paketaustausch aufgebaut bevor die eigentliche HTTP-Anfrage verschickt wird:

Wireshark kann die eigentlich HTTP-Anfrage aus dem Paketstrom wieder zusammensetzen, indem man per Rechtsklick, Auswahl von "Folgen" und "TCP Stream" den Inhalt verfolgt:
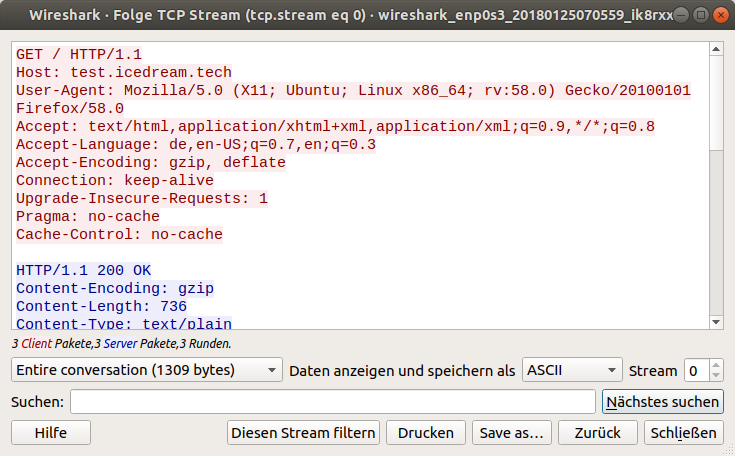
Unten stehende Anfragen und Antworten sind jeweils zusammenhängend.
GET-Anfrage
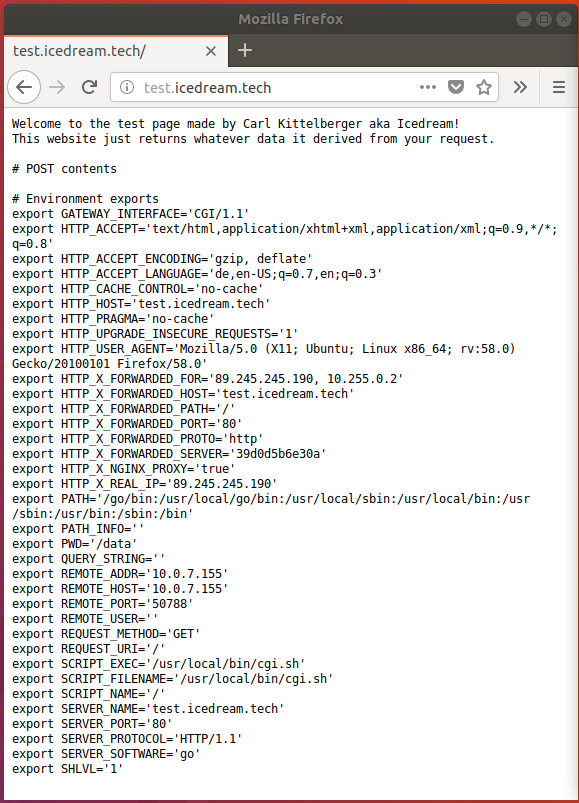
Anfrage
GET / HTTP/1.1
Host: test.icedream.tech
Connection: keep-alive
Cache-Control: max-age=0
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
Upgrade-Insecure-Requests: 1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
DNT: 1
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9
Die obige Anfrage wurde vom Chromium-Browser generiert, die Seite die hier aufgerufen wurde ist http://test.icedream.tech.
Die erste Zeile enthält die Information, dass diese Anfrage eine GET-Anfrage
ist, also keine Daten hochlädt sondern nur Daten anfordert. Sie enthält außerdem
die Information, dass Daten vom Pfad /, also dem Wurzelverzeichnis angefragt
werden. Zum Schluss gibt der Browser an, dass er auf der HTTP-Version 1.1
kommuniziert.
Nach der ersten Zeile folgen die eigentlichen Kopf- bzw. Headerinformationen zu der Anfrage:
Hostgibt an über welchen DNS-Hostnamen die Website erreicht wurde. Dies erlaubt dem Webserver Seiten für verschiedene Domains anzubieten und über den Hostnamen zu entscheiden welche Website ausgeliefert wird.Connectiongibt an ob die Verbindung nach Verarbeitung dieser Anfrage und Rückgabe der Antwort geschlossen wird oder nicht. Die meisten modernen Browser wollen die TCP-Verbindung aus Leistungsgründen aufrecht erhalten und geben daher hier den Wertkeep-alivean. Ansonsten kann hiercloseübergeben werden, dann schließt der Webserver nach Beantwortung diese TCP-Verbindung.Cache-Controlgibt Informationen zum Cachingverhalten des Browsers an. Diese Information ist in der Regel irrelevant.User-Agentgibt einige Informationen über den Client an der genutzt wurde um die HTTP-Anfrage zu generieren. In diesem Fall gibt der Browser an ein Mozilla-kompatibler Browser zu sein (Mozilla/5.0). Die meisten modernen Browser geben hier Mozilla aus historischen Gründen an und geben stattdessen nebendran genauere Informationen an. In diesem Fall folgt, dass das Betriebssystem des Browsers ein Linux-basiertes 64-Bit System mit einem Desktop auf Basis von X11 ist, sowie dass der Browser die Apple WebKit-Engine verwendet, sich wie Gecko verhält und es auch ein Chrome-Browser sowie ein Safari-kompatibler Browser ist, da Safari eine ähnliche Engine verwendet.Upgrade-Insecure-Requestsist eine Anfrage die moderne Browser mitschicken um den Webserver aus Sicherheitsgründen zu bitten, auf HTTPS umzuleiten, wenn eine HTTPS-Alternative existiert.Acceptenthält die Dateitypen, die der Browser von der Website akzeptieren würde samt Präferenzwerten.DNT(Do Not Track) ist ein Header, der von modernen Browsern mitgeschickt wird um anzudeuten, dass der Benutzer des Browsers sich ungerne tracken lassen würde.Accept-Encodinggibt an, welche Kodierformate der Browser unterstützt um den Inhalt wieder entziffern zu können, in diesem Fall akzeptiert der Browsergzip- unddeflate-kodierte Daten neben den bereits implizierten Klartextdaten. Diese Information kann der Server nutzen um Traffic-sparenden Inhalt zu liefern.Accept-Languagegibt an, welche Sprachen der Browser vorzieht. Je nach Sprache kann sich die Website dazu entscheiden, zum Beispiel die englische Version einer Seite statt der deutschen auszuliefern.
Antwort
HTTP/1.1 200 OK
Content-Encoding: gzip
Content-Length: 760
Content-Type: text/plain
Date: Mon, 22 Jan 2018 16:11:59 GMT
Server: Caddy
Server: Caddy
Server: Caddy
Vary: Accept-Encoding
............[s.8....)...j.T.....<.0..MeQ..G....o.EB..w.n..e.d..~..t.:+H.<..s.w.4T..2...-..Od.2A.JkH6P.P"y'.......u%v.B............/.
=...{(.Vj..F[(.=l.m...g./Q ?.Piru.7Z..@Q.i.tU.,.We...i.."/uuu."..le...'......r\.C:.72.b......b
.m.t..dQ$*.Z..q.....j.|.A..KK.2...6E3.E..>.....k.B.Y..z.../U...n...Uvfz..t...}^.-.N..a...,.|Op.Fq*..e..}N......S?8...D5."...9.\8..Y.z......}[.@./.[......T...J.i.H.}Xw:_.Le..:.......E..
6.J.........T.g-..;@.Dw.Gd..<.c.#m.....N...y+K.,;..u8....6.....!..F.......:m...H.t.^.g..|...S..w......w.........P..w.).nG#....!./i.q.u....b]..........j...,qnlT....J#.#...T....S.88M7*;K......I[...u/x..-.. .....Q.l......)..I...=.&z..[.SA....{..]|....p....)v.x.[r.y.....S_3....1.X.jw.N....9.C.A.../....6..7..k.Zu...r.-.".'berFq.?.....c3.?.....#1.-...
Die Header-Daten setzen sich hier wie folgt zusammen:
- Die erste Zeile gibt die HTTP-Version des Servers (
HTTP/1.1) und den Statuscode für die Anfrage same Bedeutungstext (200 OK) zurück. Content-Encodinggibt an, dass der angefragte Inhalt kodiert wurde, und wie der Inhalt kodiert wurde (in diesem Fall GZip-kodiert).Content-Lengthgibt die Länge des Inhalts in Bytes zurück. Dieser Header ist tatsächlich optional und kann für endlos streamende Daten, wie z. B. Livemedien (Icecast/Shoutcast o. Ä.) weggelassen werden.Content-Typegibt den MIME-Typen des Inhalts an. In diesem Fall wird ein Klartextinhalt zurückgegeben. Würde der Inhalt auf einer Festplatte gespeichert werden, hätte die Datei üblicherweise die Dateierweiterung.txtgehabt. Weitere Beispiele wären:text/html(HTML-Inhalte),application/javascript(JavaScript-Ressourcen)audio/mpeg(MP3-Audiodateien)video/mp4(MP4-Videodateien)- oder
image/jpeg(JPEG-Bilder).
Datebeinhaltet das aktuelle Datum und die aktuelle Uhrzeit auf dem Server.Servergibt die Software aus auf der der Webserver läuft. In diesem Fall wurden aufgrund eines Proxysetups auf dem Webserver mehrere Server-Header hintereinander verschickt.Varygibt Header an, die ein Cachingserver, der vor dem Webserver stehen könnte, auswerten kann um zu entscheiden, ob bereits zwischengespeicherter Inhalt für die gegebene Anfrage verwendet werden kann oder ob der Inhalt aktualisiert werden muss. Für einen Browser ist dieser Header in der Regel irrelevant.
Der Inhalt ist in diesem Fall kodiert. Wurde kein Content-Encoding angegeben,
wäre der Inhalt im Klartext sichtbar. Die Seite hat zwar sogenannte AJAX-Kapabilitäten, sprich sie kann bereits im Hintergrund Informationen zur Suchanfrage abschicken, die hier dafür benutzt werden Suchanfragen vor dem Abschicken der eigentlichen Suche zu liefern, aber diese Anfragen ignorieren wir hier.
POST-Anfrage
Für den Test einer solchen Frage bin ich auf die unverschlüsselte Version der Seite http://wiki.selfhtml.org gegangen und habe das Loginformular dort verwendet mit diesen Eingaben:
- Username:
testuser - Passwort:
testpasswort - Angemeldet bleiben: ja
- Vorherige Aktion: Suche nach Artikeln mit Wort
test
Natürlich sind diese Daten nicht in ihrer Nutzerdatenbank existent, wir verwenden sie hier nur zu Testzwecken.
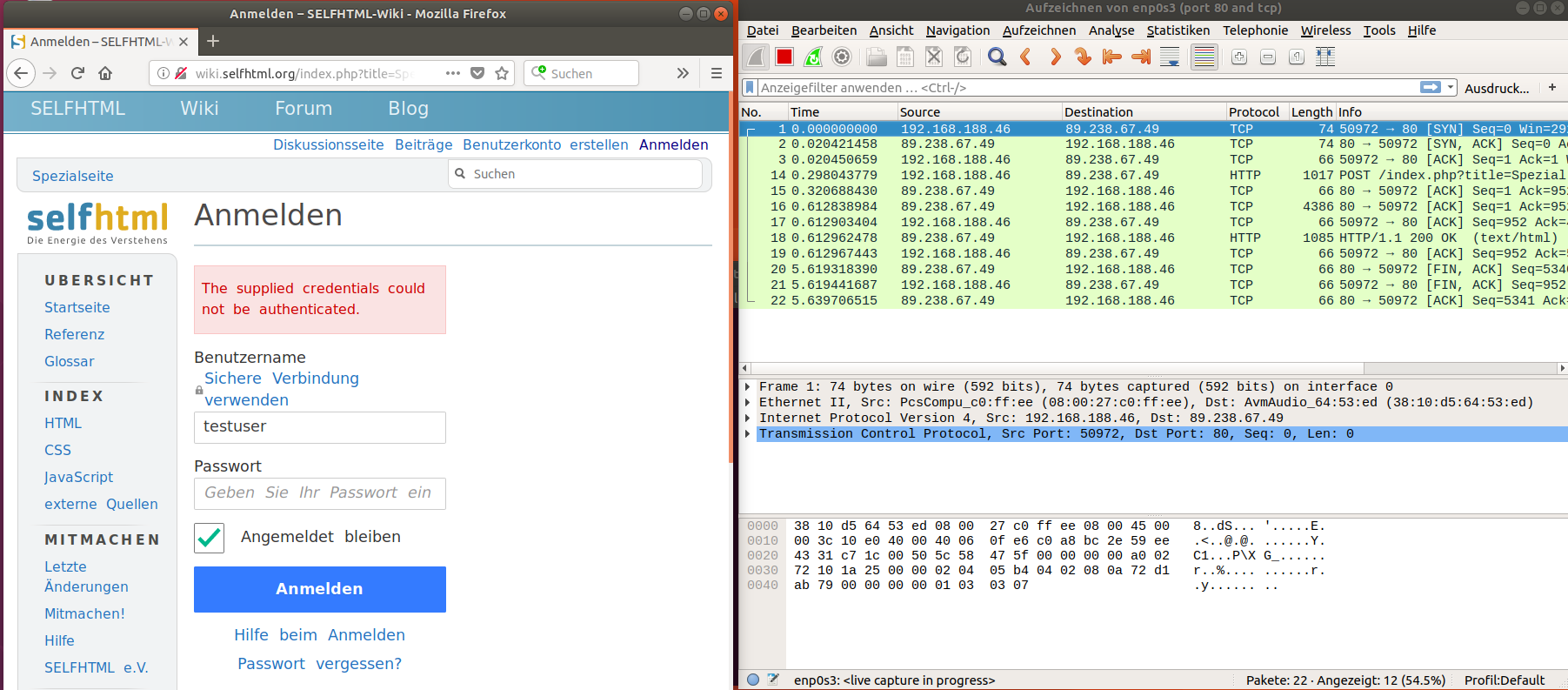
POST /index.php?title=Spezial:Anmelden&returnto=Spezial:Suche&returnquery=profile%3Ddefault%26fulltext%3DSearch%26search%3Dtest HTTP/1.1
Host: wiki.selfhtml.org
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: de,en-US;q=0.7,en;q=0.3
Accept-Encoding: gzip, deflate
Referer: http://wiki.selfhtml.org/index.php?title=Spezial:Anmelden&returnto=Spezial:Suche&returnquery=profile%3Ddefault%26fulltext%3DSearch%26search%3Dtest
Content-Type: application/x-www-form-urlencoded
Content-Length: 204
Cookie: webwiki_session=0v7632i2prj2ugc7mfjn60cbmle378fl
Connection: keep-alive
Upgrade-Insecure-Requestüs: 1
wpName=testuser&wpPassword=testpasswort&wpRemember=1&wploginattempt=Anmelden&wpEditToken=%2B%5C&title=Spezial%3AAnmelden&authAction=login&force=&wpLoginToken=c36f62fc9e3043163962cbb7530e29e35a69764f%2B%5C
Der eigentliche Unterschied zur GET-Anfrage ist eigentlich nur die Anfrage selbst. Die Antwort wird ähnlich, wenn nicht genau gleich aufgebaut sein wie bei der GET-Anfrage, da auf diese Anfrage wieder nur ein Inhalt ausgeliefert wird, auch wenn er dynamisch als Reaktion zum Login generiert wurde.
- Die erste Zeile enthält jetzt als Methode
POSTstattGET. - Der Client hat jetzt einen
Referer-Header mitverschickt um anzudeuten von welcher Seite die Daten gekommen sind. - Außerdem wurde ein
Cookiemitverschickt, den der Client bei sich gespeichert hat um dem Server bei der Zuweisung von Sitzungsdaten zu helfen. - Der Browser hat einen
Content-LengthHeader verschickt. Wie bei der Antwort zu einerGET-Anfrage auch wird hier die Länge des verschickten Inhalts angegeben, in diesem Fall von dem Inhalt der mit derPOST-Anfrage verschickt wurde.
Nach den Headerdaten folgt ein Query als Inhalt, so wie man ihn auch von dynamischen Seiten von der Addresszeile kennt. Dieser Inhalt wird zu keinem Zeitpunkt dem Nutzer direkt angezeigt, sondern der gesamte Inhalt wird direkt vom Server ausgewertet. Das ist der Sinn und Zweck einer POST-Anfrage, nämlich Daten beliebiger Länge direkt dem Server zur Verarbeitung zukommen zu lassen.
In diesem Query sind unter anderem folgende Daten enthalten (unklare oder unwichtige Daten habe ich hier weggelassen):
wpNamemit Werttestuser— unser Username.wpPasswordmit Werttestpasswort— unser Passwort.wpRemembermit Wert1— unsere Checkbox die sagt ob wir angemeldet bleiben wollen. Dafür wird auch unser Cookie verwendet.wploginattempt— Der Inhalt dieses Wertes ist der Inhalt des Absenden-Knopfs,Anmelden. Der Browser kann sich zwischen mehreren Absendknöpfen entscheiden und nur den Wert schicken, den der Benutzer auch angeklickt hat.authActionmit Wertlogin— gibt dem Server die Aktion an, die vom Formular angetriggert wird.wpLoginToken— enthält den Token für das Formular zum Login. Jedes Formular wird per sogenanntem "CSRF"-Token abgesichert um das Versenden eines solchen Formulars von einer fremden Seite zu vermeiden und der muss genau mit dem übereinstimmen was der Server erwartet.
\clearpage
Quellenangaben
Alle Quellen wurden zuletzt am 24.01.2018 geprüft.
- https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
- https://wiki.selfhtml.org/wiki/HTTP/WebDAV
- https://www.w3.org/Protocols/HTTP/1.0/spec.html
- https://www.w3.org/Protocols/HTTP/AsImplemented.html
Analysen wurden erstellt auf Basis dieser Seiten